The Price of Intelligence
Why Your AI Bill Surprises You (And Why It’s Going to Get Worse)

Every quarter or so, somebody publishes a chart showing how much cheaper AI inference has got. The line goes down impressively, and then the invoice arrives, and the invoice does not care about the line.
Uber found this out in a way that made the rounds earlier this year. They rolled out Claude Code to their engineering organisation in December 2025, management ranked engineers by AI usage on internal dashboards, adoption jumped from 32 percent to 84 percent of a five-thousand-person team, and by April the entire 2026 AI budget was gone — four months into the year. Per reporting by The Information, the CTO said the company is “back to the drawing board” on AI budgeting.
Monthly API costs were running between five hundred and two thousand dollars per engineer. Ninety-five percent of Uber’s engineers now use AI tools monthly. Seventy percent of committed code originates from AI. The tool worked exactly as designed, and that was the problem.
Gartner reckons more than 40 percent of agentic AI projects will be cancelled by the end of 2027, citing escalating costs and unclear value — which is quite something for a category that every vendor roadmap is pointing at. Somebody in procurement is going to have a difficult quarter.
The FinOps team has had a year. Some of them have had eighteen months. The ones at firms with agentic deployments have developed a facial expression usually reserved for people who have just discovered their waiter must have misheard them clearly say “your finest, cheapest bottle of wine, please”.
The Token Economy Has a CFO Problem
Most finance teams will sign off on significant AI spend if they can forecast it, but what they cannot stomach is a line item that defies modelling – spend that could be fifty thousand or five hundred thousand next quarter depending on how enthusiastically the engineering team adopts the new agent framework. That conversation tends to happen in smaller rooms, with worse coffee, and a whiteboard nobody has cleaned since March.
The issue is structural. When software cost scaled with headcount – buy fifty licences, get an invoice for fifty licences – finance teams could forecast with tolerable precision. AI pricing does something else entirely – one employee can trigger thousands of model calls in an afternoon; another might trigger none. The invoices arrive as what PYMNTS described as “dense ledgers of token counts, model tiers and throughput metrics” that finance teams cannot easily map back to business activity. Eight out of ten CFOs at large companies report being materially affected by AI adoption challenges.
SaaS invoices itemised things people understood but these AI invoices require a translator and a lot of vocabulary to decipher. The cost driver changed from who has the seat to what work actually happened, and the forecasting muscle built over a decade of subscription software stopped being useful overnight. Every additional SaaS user after the first costs the provider nearly nothing to serve but with AI workloads, the compute costs accumulate with all activity. The millionth query costs the same as the first – that is a fundamentally different marginal cost structure, and it shows up in every invoice that catches finance off guard.
Inference now accounts for 85 percent of enterprise AI budgets, up from roughly 20 percent in 2023. Ninety-eight percent of FinOps practitioners are now managing AI spend, up from 31 percent in 2024, per the FinOps Foundation’s latest report — so the discipline exists, but the problem is outpacing it.
Cheaper Tokens Produce More Tokens
The price decline is real, and it is steep. According to Epoch AI research – peer-reviewed methodology, not a vendor blog – the cost to run an LLM at a fixed performance level has been halving roughly every two months since early 2024. The rate varies (anywhere from 9x to 900x per year depending on the model family), but the median decline is around 200x annually.
A query that cost twenty dollars per million tokens in late 2022 costs seven cents today. Twenty dollars to seven cents in three years. That should make everything cheaper. Enterprise AI spending surged 320 percent in 2025. Average enterprise AI budgets grew from 1.2 million to 7 million dollars between 2024 and 2026. Gartner pegs global AI spending at 2.52 trillion dollars for 2026 – forty-one percent of all IT spending worldwide.
The mechanism is not complicated once you see it. Cheaper tokens make new use cases economically viable. Agentic workflows that fire API calls in loops. Chain-of-thought reasoning that burns through output at three to ten times the rate of a simple chat completion. And tellingly, as velocity increases, the people driving the agents are increasingly time-poor; the temptation to pray and spray with reasoning cranked up to “max” rather than intensively babysit a cheaper model becomes harder to resist. This creep from the cheap model tier to the expensive one can be hard to track and harder still to manage.
Each new use case consumes orders of magnitude more tokens per business outcome than the last, total consumption rises faster than unit price falls and the savings get consumed before they reach the spreadsheet.
Like a lot of emergent phenomena in artificial intelligence, there is an old name for this. It has been around since 1865, when William Stanley Jevons noticed that James Watt’s more efficient steam engine did not reduce coal consumption – it increased it, because efficiency made coal-powered industry viable in places it previously was not. Cheaper inference produces more inference. The mechanism is identical. And unlike Watt’s engine, the efficiency gains in AI inference are compounding monthly, which means the paradox is accelerating rather than playing out over decades.
The Three Forces That Eat Your Savings
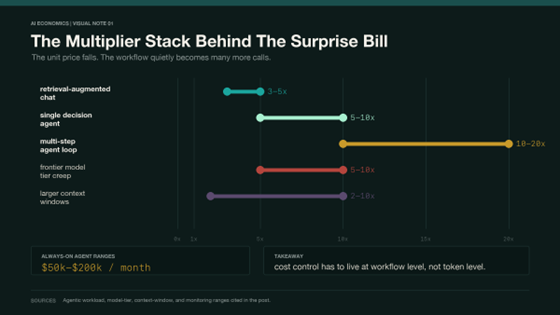
The Jevons dynamic gets worse when you look at what enterprises are actually deploying. Three forces are compounding on top of the basic paradox.
The first is agentic architecture. A standard chatbot interaction is the baseline – call it one unit of token consumption. Add retrieval-augmented generation and you are at three to five times that. Give the agent a single decision-making step and it is five to ten times. Let it loop through multi-step reasoning, retrying and branching, and you hit ten to twenty times the baseline.
Industry estimates put always-on monitoring agents – the kind that watch production systems and act autonomously – at costs between fifty thousand and two hundred thousand dollars per month, depending on workload and model choice. The exact figures vary, but the failure mode is not exotic: an agent retries a failed call in a loop and nobody notices until the invoice arrives. One AI governance firm has reported uncapped agent sessions leaking hundreds of millions of dollars in cloud spend across its Fortune 500 clients. Treat the number as directional, but the pattern is not hard to believe once you have seen an agent work enthusiastically at the wrong thing.
The second is model-tier creep. Teams prototype on the cheap tier, discover it cannot handle the edge cases, and migrate to the frontier model. The per-token cost jumps five to ten times yet during the intoxicating rush of executing real change at pace, nobody remembers to nudge the finance team to refresh the budget forecast.
The third is context window inflation – as models accept longer inputs, prompts expand to fill them and behaviours change accordingly. Anthropic’s 1M token context window is the best current example. Two to ten times more input tokens per call than the same query required eighteen months ago – and why bother with time-consuming context compactions when you have a million of them to play with? The meter runs faster even when the work looks identical. These are structural forces, and you cannot negotiate them away in a vendor call.
The Subsidy Nobody Talks About at the Right Volume
There is also the small matter of who is paying for your current prices. OpenAI is burning roughly $47m a day. Their projected loss for 2026 is $14bn. Cumulative projected burn through 2029 has reached the positively giddy sum of $218bn – a figure that doubled from internal projections just two quarters ago, per Sherwood News reporting.
They are not expecting profitability until 2029 at the earliest. Five and a half percent of their 900m weekly users are paying. The rest are being subsidised by $122bn in funding raised at an $850bn valuation.
Which is fine because that is how venture capital works. You buy attention now and you charge for it later – remember when Uber rides cost less than a fiver and then we got surge pricing? Anthropic is doing the same thing – they hit a $30bn annualised revenue run rate in April, surpassing OpenAI for the first time whilst spending four times less on training, but their path to cash-flow positive just slipped from 2027 to 2028. The money going out the door (roughly $19bn in combined training and inference operations for 2026) still exceeds what comes in.
The rates you see on the pricing page are customer-acquisition rates, funded by the largest private rounds in history. The party has a finite amount of champagne, and somebody is going to notice the empties before the speeches are done. What happens to your unit economics when the people funding your artificially cheap inputs decide they would like their money back? Enough has been written about how Cory Doctorow’s Enshittification thesis applies here but the impact of OpenAI’s for-profit conversion and IPO trajectory demanding eventual profitability is likely going to dwarf prior notable examples like Netflix, Unity, Reddit etc.
Where this matters for budget planning though, is that Jevons paradox does not apply uniformly. Where demand is elastic, cheaper inference creates more inference. Agentic workflows, creative generation, research and exploration – these have no natural ceiling. When asking is cheap, people ask more. Uber’s engineers went from 32 percent to 84 percent adoption in months precisely because the cost of using the tool dropped below the friction of not using it.
But for bounded workloads – document classification processing ten thousand invoices a day, compliance checking against a fixed regulatory corpus, batch pipelines with throughput determined by business volume rather than compute cost – cheaper inference just means cheaper invoices. The food demand analogy from economics: large improvements in farming productivity lowered food prices without proportionally increasing consumption, because demand is bounded by biology. Ten thousand invoices a day is ten thousand invoices a day regardless of what inference costs.
The problem, for anyone trying to plan a budget, is that agentic AI – the fastest-growing category, the one every vendor roadmap is pointing at – is elastic by nature.
The Price Problem Is Only the Obvious Problem
So. Per-token costs are falling at a rate that should make everything cheaper. Total bills are rising because consumption is elastic and growing faster than prices fall. The venture capital subsidy disguising the true cost of inference has a finite shelf life. The mental models CFOs built for a decade of SaaS pricing do not map onto a world where one developer can burn two thousand dollars a month in API calls without anybody noticing until the quarterly review. And the fastest-growing workload category – agentic AI – is the one where Jevons paradox bites hardest.
None of this is going away. It is worth understanding, worth planning for, and worth having the slightly uncomfortable budget conversation about sooner rather than later.
But the cost problem – real and structural as it is – is only the obvious problem. The subtler one is that what you are paying for – the model, the capability, the thing you evaluated and approved and budgeted for – may not be what you are getting. That deserves its own conversation.
References
Epoch AI - LLM Inference Price Trends – Peer-reviewed analysis of inference cost decline rates
Gartner - Worldwide AI Spending to Total $2.52 Trillion in 2026 – Global AI spending and IT share figures
Gartner - Over 40% of Agentic AI Projects Will Be Cancelled by 2027 – Agentic project cancellation forecast
Briefs.co - Uber Torches Entire 2026 AI Budget on Claude Code – Uber case study and per-engineer cost data
PYMNTS - CFOs Scramble as AI Pricing Breaks Traditional SaaS Billing – CFO challenges with consumption-based AI invoicing
FinOps Foundation - State of FinOps 2026 – FinOps practitioner survey on AI spend management
Sherwood News - OpenAI’s Planned Cash Burn Now Doubling – OpenAI $218B cumulative burn projections
Yahoo Finance - OpenAI’s Own Forecast Predicts $14B Loss – OpenAI 2026 financial projections
WIRED - The Enshittification of TikTok – Cory Doctorow’s platform decay thesis
VentureBeat - Anthropic Hits $30 Billion Revenue Run Rate – Anthropic revenue milestone and growth
Claude - 1M Context Is Now Generally Available – Anthropic 1M context window rollout and standard pricing
Oplexa - AI Inference Cost Crisis 2026 – Vendor analysis of agentic cost multipliers and enterprise workload range
Waxell - AI Agent FinOps Cost Enforcement – Vendor-reported uncapped agent session spend data

Tom’s spent the last twenty years helping insurers make sense of their systems and occasionally their existential crises. He’s worked across architecture, data, and transformation. He co-founded Metamorphic with Dan to prove that legacy systems aren’t relics. They’re the company’s real memory.