The Product You Think You Bought
Model Drift, Quiet Degradation, and Licences That Are Not What They Claim

In April 2026, Stella Laurenzo, Director of AI at AMD, filed a GitHub issue documenting something specific and uncomfortable. Across 6,852 Claude Code sessions, her team had tracked 234,760 tool calls and 17,871 thinking blocks. Code reads per session had dropped from 6.6 to 2.0 over the course of a month. The model was doing less work per interaction, and nobody at Anthropic had mentioned it. Her team switched providers.
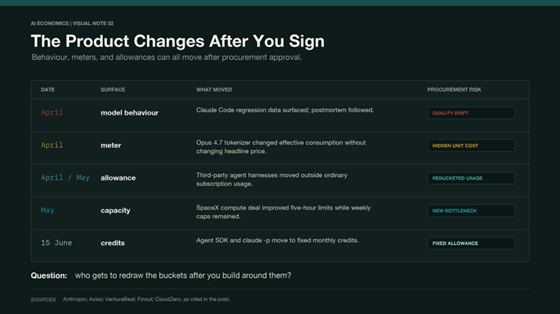
The problems, it turned out, had started seven weeks earlier. Three separate engineering changes had silently degraded the product - a default reasoning effort reduced from high to medium, a caching bug that cleared context every turn instead of once, and a system prompt that told the model to use fewer than twenty-five words between tool calls. All three changes passed multiple human and automated code reviews, unit tests, end-to-end tests, automated verification, and dogfooding. The quality gates that were supposed to catch this sort of thing did not catch this sort of thing. Anthropic published a postmortem seven weeks after the first degradation began, which is about six weeks and five days later than most enterprise customers would have preferred.
The Model Changes After You Sign
It had happened before. The previous August, three infrastructure bugs at the same company had caused output corruption - including random Thai and Chinese characters appearing in English responses from a TPU misconfiguration - and affected roughly 30 percent of Claude Code users before full resolution six weeks later. Those were infrastructure failures rather than deliberate quality reductions, but the effect on the customer was identical: the product got worse and nobody told them; in fact, Anthropic downplayed the issue and ignored the growing chorus of disgruntled users on LinkedIn and Reddit. The timing of this crunch right before Anthropic’s CEO Dario Amodei announced a new $13bn funding round raised more than a few eyebrows – had they scrimped on compute to make their numbers look better? Who knows.
There is a distinct mechanism worth understanding here – Amodei has publicly described the company as “compute-constrained,” with new infrastructure requiring 12-24 months to materialise. The practical consequence showed up in March 2026, when the company introduced stricter usage limits during peak weekday hours. Max subscribers - the 5x and 20x tier - were hitting their daily limits in nineteen minutes instead of the documented five hours. Claude Code itself was burning roughly 40 percent more tokens per interaction than it had two versions earlier. So model quality can degrade for at least two distinct reasons: deliberate optimisation decisions (changing reasoning effort to reduce latency) and infrastructure pressure the customer cannot see or predict. Both produce the same result - the thing you are renting today may perform differently tomorrow - but they have different implications for anyone trying to plan around them.
And the degradation is only one dimension of instability, as anyone trying to keep up with the dizzying pace of model releases will be able to predict - the models themselves have quite short shelf lives. Azure sets retirement dates for its hosted models programmatically at launch: generally available model versions get an eighteen-month retirement date, with the replacement model selected roughly ninety to a hundred and twenty days before retirement. Two GPT-4o versions on Azure retired on 31 March 2026 and were auto-upgraded to GPT-5.1 on the Standard SKU. OpenAI also retired GPT-4o, GPT-4.1, GPT-4.1 mini, and o4-mini from ChatGPT in February 2026, while noting that API access was unchanged at that point. The practical lesson is simple enough: every calendar is a product dependency, and every product dependency eventually lands in somebody’s migration plan.
The model you benchmarked in January may be deprecated by June, silently degraded by April, or superseded by something three times better and ten times cheaper by March. Intelligence, it turns out, is perishable - and the accounting profession has not caught up. Enterprises are amortising AI investments over three to ten years under IAS 38 norms designed for software with a predictable useful life. The effective shelf life of the AI models underneath those investments is three to six months. Nobody has written an accounting standard for that mismatch, which is itself a useful data point about how new this problem is.
Three Cousins, Not Identical Twins
There is another way the product changes between the demo and production, and it lives in the maths rather than the infrastructure.
Quantization - the process of running a model at lower numerical precision to reduce memory and compute requirements - is standard practice across every major provider and self-hosted deployment. A study published at ACL 2025, covering over half a million individual evaluations across the Llama 3.1 family, found that FP8 quantization – a saving of 50% of the memory needed to run a model over the customary native precision of F16, is essentially lossless. INT8 costs you one to three percent on most benchmarks. INT4 is competitive with INT8, meaning the quality gap is real but small enough to pass most automated testing. That last part is precisely why it matters. On code generation specifically, 4-bit models recovered 98.9 percent of full-precision accuracy per the Red Hat evaluation. The 1.1 percent gap does not sound alarming until you consider that the cases where it surfaces are, by definition, the ambiguous edge cases and creative reasoning tasks that justified using a frontier model in the first place. A separate study in Nature found that moderate quantization shows gradual, manageable degradation - but aggressive compression (3-bit, 2-bit) hits a catastrophic cliff where performance collapses rather than declining gracefully.
The version on the provider’s benchmarking page, the version in their hosted API, and the version running on your local GPU may be three cousins rather than identical twins. The quality differences between BF16 and INT4 are small enough to look fine on a dashboard and real enough to matter in the cases your procurement team cannot easily test for. Then there is the meter itself. Anthropic released Opus 4.7 in April 2026 with a new tokenizer. The per-token price did not change. The tokenizer produces up to 35 percent more tokens for the same input text, with the upper end hitting code, structured data, and non-English content hardest. A coding agent workload costing three hundred dollars a month on Opus 4.6 could run to four hundred and five dollars on 4.7 at the ceiling estimate - though Finout, whose analysis surfaced the issue, labels their projections as illustrative rather than universal and recommends replaying real traffic to measure actual impact. The typical range for most workloads falls between 12 and 27 percent. (The price did not change; the meter did.)
Subscription allowances are becoming just as mutable as the models themselves. Anthropic added Claude Design to Pro, Max, Team, and Enterprise plans, but meters it through its own allowance rather than simply expanding the existing pool. In April, third-party agent harnesses such as OpenClaw were pushed out of standard Claude subscription usage and into extra usage or API billing. In May, a SpaceX compute deal let Anthropic double Claude Code’s five-hour limits and remove peak-hour reductions, but the weekly and feature-level caps remained part of the product. From 15 June 2026, Agent SDK usage, claude -p, Claude Code GitHub Actions, and third-party Agent SDK apps move into a separate monthly credit: $20 on Pro, $100 on Max 5x, and $200 on Max 20x.
That is not straightforwardly more generous or less generous. It is re-bucketing. The allowance changes shape, the meter moves, and the workflow that looked economical under one set of plan rules can become a different calculation under the next. This is what subsidy withdrawal tends to look like before the rate card changes. The public price stays familiar, but the unprofitable edge cases are fenced off one by one – take a bow, Cory Doctorow. Investors of any kind, especially post-IPO retail investors, tend to take a pretty dim view of selling a dollar of compute for sixteen cents. They become less sentimental about it once the growth story has to share a page with margin.
The Licence You Did Not Read Until Production
The models everyone calls “open source” are mostly open weight - a distinction that sounds pedantic until you read the licence. The Open Source Initiative published a formal definition in late 2024 requiring training data details, full training code, and model weights. By that standard, virtually none of the popular models qualify. What they offer is the weights, a custom licence, and a set of terms that vary from the genuinely permissive to the quietly alarming - and the variation between model families is the part most engineering teams discover too late. The usual pattern is that an engineering team picks a model for its benchmarks, builds a proof of concept, gets executive buy-in, and then somebody in legal reads the licence three weeks before production.
Meta’s Llama licence includes a threshold at 700 million monthly active users across your entire product, including affiliates. That is product-level usage, not just the AI feature. Exceed it and you must request a licence from Meta before crossing the threshold, granted at their sole discretion. There is also a competitor restriction covering social networking, messaging, VR, and AI assistant offerings, plus a training ban: you cannot use Llama or its outputs to improve any non-Llama model. Research from SoftwareSeni found that 85.8 percent of the 27,000 Llama derivatives on Hugging Face fail the naming convention requirement in the licence they agreed to.
Qwen runs on mixed terms. Some models ship under Apache 2.0 (genuinely permissive); others use the Tongyi Qianwen Licence with a 100 million monthly active user threshold for larger models. The thresholds for newer variants are, per SoftwareSeni’s analysis, “not publicly documented” - which makes compliance verification a creative exercise. More recently, Qwen3.5-Omni launched as a proprietary API-only release, breaking the open-weight tradition entirely. Mistral used to restrict production use of its larger models under the MNPL licence - “development and evaluation only,” meaning production deployment without a commercial agreement was technically a licence violation. In 2026, Mistral shifted to Apache 2.0 for its newest models. Good news, unless your compliance framework was built on the assumption that licence terms are stable.
MiniMax is the 2026 example that makes the issue less theoretical. M2.7 arrived with strong published benchmarks - 56.22 percent on SWE-Pro and 57.0 percent on Terminal Bench 2 - and open weights, then its licence landed as non-commercial by default: personal, academic, and research use are permitted, but commercial use requires prior written authorisation from MiniMax. The explanation matters as much as the term sheet. Ryan Lee, MiniMax’s Head of Developer Relations, said the tighter licence was aimed at inference providers that had served degraded versions of earlier MiniMax models - wrong templates, aggressive quantization, sometimes not even the right model - and left users thinking the model itself was crap compared with its benchmarks. MiniMax then published a Provider Verifier so third-party deployments could be tested against the official model behaviour. That is the open-weight problem in miniature: the thing in the provider dropdown and the thing on the benchmark chart may share a name while being materially different products.
DeepSeek is the genuinely permissive outlier. MIT licence, no MAU threshold, no competitor restrictions, no copyleft requirement. The catch, such as it is, lives in a different layer: the training data provenance is undocumented. The model weights carry MIT permissions, but the data used to train those weights has no publicly documented robots.txt compliance, copyright clearance, or licensing audit. Model permissions and training data risk are separate questions, and the MIT licence only answers one of them. Across model families, research from February 2026 found that 96.5 percent of datasets and 95.8 percent of models are missing the licence text needed to make their permissive labels actually mean anything.
The resulting conversation when legal does finally read the licence is not fun for anyone involved, and it occasionally features the phrase “unexpected costs from Alibaba”, which is a sentence that tends to hang in a room. The CloudBees 2025 DevOps Migration Index puts the average loss per platform migration at $315,000, with 57 percent of IT leaders spending over a million dollars annually on migrations. AI model migration may be technically simpler than a full platform swap - swapping an API endpoint is hours of work, not months - but the testing, revalidation, and prompt re-engineering costs are the real expense, and they grow with every month of operational history.
What This Means for Procurement
Procurement teams built for buying software licences are not equipped for a market where the product changes shape between the demo and the invoice. Everything described above - the model drift, the quantization differences, the tokenizer recalibrating the effective price, the licence terms that vary between model versions - represents risk that nobody put in the vendor assessment template. I suspect nobody is rushing to add it.
The institutional gap is real but addressable. The next vendor review should be verifying things that traditional software procurement never had to consider: whether the provider offers model version pinning, and for how long; what deprecation notice period is contractually committed (not just the current default); what quantization precision will be served in production versus what was demonstrated in the evaluation; whether tokenizer changes trigger notification or are applied silently; and whether licence terms for the specific model version being deployed have been reviewed by someone who reads licence agreements rather than README files
The venture subsidy means you are evaluating at prices that will change and the instability explored here means you are also evaluating a product that will change. Both the price and the product sit on foundations that shift - not through malice, but through the ordinary mechanics of a market that has not finished forming. The demo was not the product, and the gap between them is wide enough to require its own line in the risk register.
Rate card comparisons between providers are no longer sufficient on their own - a procurement team comparing two models at nominally identical per-token prices may be comparing different effective costs (tokenizer differences), different quality levels (quantization differences), and different legal obligations (licence differences). The surface similarity hides meaningful divergence, and the only way to surface it is to test with your own workloads, under your own conditions, with your own legal team reading the actual terms.
Should You Just Do It Yourself?
The instability described above - models that degrade, quantization that changes what you are running, tokenizers that quietly shift the economics, licences that surprise legal at the worst possible moment - raises a question that most enterprise technology leaders are already forming by this point. If the rented product keeps changing shape, should you just run your own?
The question is reasonable, but the honest answer has more moving parts than the question implies. Self-hosting offers genuine control over model versions, quantization levels, and data governance – and most critically, in my personal view, self-hosting offers predictability that is notably absent from commercial token provider offerings. This applies to both sides of the equation – the costs as well as the outcome. But it also comes with its own set of costs, supply constraints, and operational complexity that deserve the same sceptical scrutiny applied to the buy side.
Those lessons have been taught before but, as the saying goes, those who learned them in the past cannot learn them for you today.
References
· The Register - AMD AI Director Documents Claude Code Decline - Stella Laurenzo incident reporting and provider switch
· GitHub Issue #42796 - Claude Code Quality Regression - Laurenzo’s original data: 6,852 sessions, 234,760 tool calls
· Anthropic - April 23, 2026 Postmortem - Three engineering changes that degraded Claude Code quality
· Anthropic - September 2025 Postmortem - Three infrastructure bugs including TPU misconfiguration
· ACL 2025 - “Give Me BF16 or Give Me Death?” - Peer-reviewed quantization study with 500K+ evaluations
· Red Hat - Quantized LLM Evaluations - INT4 code generation accuracy benchmarks
· Nature npj AI - Phase Transitions in LLM Compression - Catastrophic collapse thresholds in aggressive quantization
· Finout - Claude Opus 4.7 Pricing Analysis - Tokenizer cost impact with methodology caveats
· CloudZero - Opus 4.7 Pricing - Independent tokenizer cost verification (12-27% typical range)
· Anthropic - Introducing Claude Design - Claude Design availability and plan inclusion
· Claude Help Center - Claude Design Usage and Pricing - Separate Claude Design allowances and weekly limits
· Anthropic - Higher Usage Limits and SpaceX Compute Deal - Five-hour Claude Code limit increase and peak-hour change
· Claude Help Center - Agent SDK with Claude Plan - June 15 Agent SDK and claude -p monthly credit change
· Axios - Anthropic Tightens Claude Limits - Commentary on flat-rate AI subscriptions under agentic usage
· VentureBeat - Anthropic Reinstates Third-Party Agent Usage With a Catch - Reporting on OpenClaw, third-party agents, and credit-pool mechanics
· MiniMax M2.7 - GitHub Repository - M2.7 benchmark claims, model card, and licence link
· MiniMax M2.7 - Licence - Non-commercial licence and prior-authorisation requirement for commercial use
· MiniMax Provider Verifier - Official verifier for third-party MiniMax deployments
· Decrypt - MiniMax Drops State-of-the-Art AI Agent Model, Then Quietly Changes the License - Reporting on licence change rationale and degraded third-party providers
· WCR Legal - Llama 3 Licence Analysis - 700M MAU threshold and competitor restrictions
· SoftwareSeni - Open-Weight Licence Comparison - Cross-model licence terms for commercial use
· Microsoft Learn - Azure Foundry Model Retirements - 18-month lifecycle and deprecation policy
· OpenAI - Retiring GPT-4o and Older ChatGPT Models - February 2026 ChatGPT model retirements and API caveat
· PKF Littlejohn - Capitalising AI Tools Under IAS 38 - Accounting treatment of AI intangible assets
· CIO Dive - Migration Costs - CloudBees DevOps Migration Index ($315K average loss)

Tom’s spent the last twenty years helping insurers make sense of their systems and occasionally their existential crises. He’s worked across architecture, data, and transformation. He co-founded Metamorphic with Dan to prove that legacy systems aren’t relics. They’re the company’s real memory.